
In the race to deliver curative oncology, data has become simultaneously our most powerful asset and our most critical liability. Artificial intelligence is compressing decades of immunological research into months of computation — yet a systemic failure in data verifiability is preventing those breakthroughs from reaching patients at the speed science now makes possible. Closing this "Trust Gap" requires not better algorithms, but better infrastructure.
The Immunotherapy Landscape: Biology at Computational Scale
We are operating at an inflection point in immuno-oncology. The therapeutic arsenal available to clinicians today encompasses modalities unimaginable a decade ago: immune checkpoint inhibitors (ICIs) targeting the PD-1/PD-L1 and CTLA-4 axes; chimeric antigen receptor T cell (CAR-T) therapies engineered with patient-derived lymphocytes transduced via lentiviral vectors; bispecific T cell engagers (BiTEs) simultaneously binding tumour-associated antigens and CD3ε; and personalised neoantigen cancer vaccines designed against patient-specific somatic mutational landscapes. These are not iterative refinements of existing oncology practice — they represent a fundamental reconceptualisation of cancer as an immunologically tractable disease.1
The biological complexity underpinning these therapies demands an equivalent complexity in data infrastructure. A single Phase II CAR-T trial now generates multi-petabyte datasets encompassing bulk and single-cell RNA sequencing, spatial transcriptomics, T cell receptor (TCR) repertoire profiling, multiplex cytokine panels, and continuous biometric telemetry — distributed across CRO platforms, academic biorepositories, and sponsor EDC systems that were never designed to interoperate at this resolution or velocity.2
Where the Pipeline Breaks: The Structural Barriers to Progress
The rate-limiting factor in immunotherapy development today is not primarily biological. It is epistemic — a systemic inability to prove, to the satisfaction of regulators, ethics boards, and institutional investors, that the data underpinning a given body of research is traceable, unaltered, and legitimately consented from source to regulatory submission. As FLEXBLOK's recent article on clinical trial credibility makes clear, the traditional answer — siloed systems, manual audits, and institutional trust — is no longer architecturally sufficient.3
Across multi-site trials operating simultaneously in the United States, the United Kingdom, Singapore, India, and the EU, the same structural failure modes recur with costly regularity:
- Fragmented Data Silos Blocking Federated AI Multi-omics datasets, eCRF entries, biobank aliquots, and PBMC processing records are distributed across CRO LIMS platforms, sponsor EDC systems, and third-party sequencing facilities — each operating on incompatible schemas with no unified audit trail. This fragmentation is the primary technical barrier to federated machine learning across trial consortia, and to meeting ALCOA+ data integrity principles (Attributable, Legible, Contemporaneous, Original, Accurate — plus Complete, Consistent, Enduring, and Available) demanded by regulators.
- Unverifiable AI Training Data Provenance Under FDA 21 CFR Part 11 and the EU AI Act's high-risk AI provisions, clinical AI models must demonstrate full traceability of their training data — including consent attestation, preprocessing lineage, and access logs. Without on-chain provenance, AI-generated biomarker signatures and ICI response predictions cannot be submitted as primary regulatory evidence, regardless of their predictive accuracy or clinical plausibility.
- Dynamic Consent Failure Across Jurisdictions Multi-national trials must simultaneously satisfy the GDPR's data minimisation principles, HIPAA's PHI protections, India's Digital Personal Data Protection (DPDP) Act, and Singapore's PDPA — each with distinct consent architecture requirements. Retrospectively reconstructing consent audit trails from disparate eCRF systems for regulatory inspection is a persistent source of trial delay and sponsor liability, particularly in Phase II and III programmes.
- Preclinical Reproducibility Gaps Undermining Regulatory Packages Disconnected chain-of-custody records for primary biological material — patient-derived xenograft (PDX) samples, primary tumour biopsies, cryopreserved PBMCs — make cross-institutional replication of preclinical findings structurally unreliable. When ICH M3(R2) and GLP reproducibility requirements cannot be satisfied with verifiable documentation, regulatory agencies face little choice but to invalidate the preclinical data package, adding years to approval timelines.
"Biotech's greatest breakthroughs are stalled not by scientific limits, but by organisational silos. Auditors and regulatory bodies demand traceability, accountability, and ethical compliance — and fragmented consent records, incomplete processing histories, and missing metadata expose entire research programmes to invalidation."
— FLEXBLOK: Blockchain for BiotechAI as the Discovery Engine of Precision Oncology
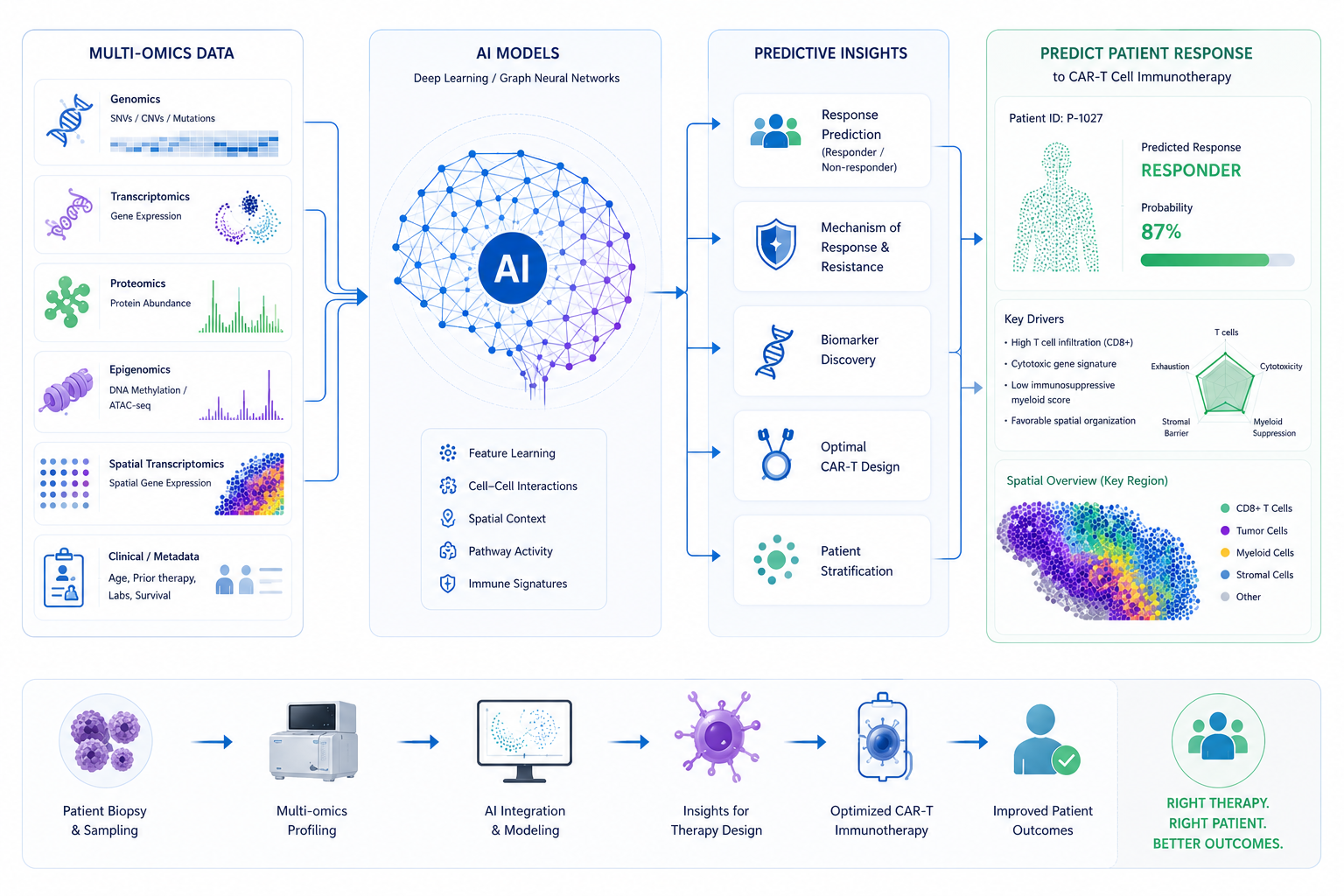
Despite these infrastructural constraints, artificial intelligence is delivering validated, peer-reviewed advances across every stage of the immunotherapy pipeline. Nature Biotechnology's 2025 annual research review identified accelerated convergence between AI, genomic medicine, and immunotherapy as the defining trend of the year — a convergence that is deepening further in 2026.2
Neoantigen Discovery and Personalised Vaccine Design
Tumour-specific somatic mutations generate mutant peptides that, when presented on MHC class I molecules in appropriate HLA haplotypic contexts, can prime cytotoxic T lymphocyte responses against malignant clones. Transformer-based deep learning models trained on IEDB binding affinity datasets, proteasomal cleavage probabilities, and TAP transport efficiency scores now rank neoantigen candidates with sufficient precision to guide patient-specific mRNA vaccine constructs within days of whole-exome sequencing — compressing timelines from twelve to eighteen months down to weeks in leading academic medical centres.1
CAR-T Cell Engineering and In Vivo Delivery
Reinforcement learning algorithms optimise the selection of single-chain variable fragment (scFv) domains for improved antigen binding affinity and specificity, while simultaneously minimising predicted off-tumour cross-reactivity — a critical safety consideration given the cytokine release syndrome (CRS) and immune effector cell-associated neurotoxicity syndrome (ICANS) risk profiles associated with CAR-T constructs. Concurrently, AI-guided lipid nanoparticle (LNP) formulation is enabling in vivo CAR-T reprogramming of endogenous T cell populations, bypassing the resource-intensive ex vivo lentiviral transduction and GMP manufacturing pipeline entirely.2
Immune Checkpoint Inhibitor Response Prediction
Multimodal AI architectures integrating tumour mutational burden (TMB), microsatellite instability (MSI) status, CD8+ tumour-infiltrating lymphocyte (TIL) density derived from computational pathology, and radiomic features extracted from pre-treatment CT imaging are now achieving AUC values of 0.70–0.95 across diverse tumour histologies in prospective validation cohorts.4 The translational implication is clinically significant: patient stratification prior to ICI initiation — sparing non-responders from costly and immunotoxic therapy while directing benefit to predicted responders.
A fundamental constraint applies universally across all of these advances: AI generates insights, but it cannot generate trust. A neoantigen ranking model trained on genomic data lacking verifiable consent documentation will not produce acceptable regulatory evidence. A federated learning model whose training datasets lack traceable provenance cannot support a submission dossier. The predictive validity of the algorithm is irrelevant if the data infrastructure beneath it remains opaque to auditors and regulators.
Blockchain for Biotech: The Infrastructure of Scientific Truth
This is where enterprise blockchain transitions from a speculative technology concept to a mission-critical biomedical utility. Permissioned distributed ledger technology — deployed on protocols such as Hyperledger Besu — acts as the foundational trust layer for clinical and translational data. Every data transaction is cryptographically hashed, appended to a Merkle-tree structure, and recorded on an immutable ledger that any authorised participant — sponsor, CRO, ethics board, regulator — can verify independently, in real time, without centralising sensitive patient data.5
This is not speculative adoption. Published bibliometric analyses of the clinical blockchain literature confirm that pharmaceutical and biotech sponsors are actively investing in blockchain to accelerate drug development, reduce audit burden, and achieve simultaneous compliance across FDA, EMA, CDSCO, and HSA jurisdictions.6 For immunotherapy organisations, enterprise blockchain delivers across five non-negotiable dimensions:
- Immutable AI Data Provenance and Regulatory Defensibility Every dataset input to an AI model — genomic sequences, spatial transcriptomics matrices, flow cytometry panels — carries an on-chain certificate recording its biobank origin, chain-of-custody history, consent attestation, preprocessing lineage, and all access events. This makes AI-generated clinical endpoints auditable under FDA 21 CFR Part 11 and the EU AI Act's high-risk AI provisions without requiring separate retrospective validation studies. FLEXBLOK supports OpenLineage-standard model lineage capture anchored to the blockchain, creating a complete and auditable history of every AI model iteration.
- Smart Contract-Managed Dynamic Patient Consent Patient consent is encoded as an executable smart contract on the blockchain. If a participant revokes or modifies their data-sharing permissions, access is cryptographically blocked across all connected LIMS, EDC, and CTMS systems — globally, in real time — and the event is immutably logged. This architecture satisfies the dynamic consent requirements of GDPR, HIPAA, India's DPDP Act, and Singapore's PDPA within a single verifiable framework, eliminating the cross-border consent fragmentation that routinely delays multi-national trial submissions.
- Tamper-Proof Clinical Trial Records from Enrolment to Submission Protocol amendments, MedDRA-coded adverse event narratives, SAE reports, RECIST efficacy assessments, and patient-reported outcomes are timestamped on-chain at the moment of generation — functioning as a cryptographic "data notary" that mathematically proves the EDC record and the eTMF source document match. Retrospective manipulation of clinical data becomes computationally impossible, giving regulators, IRBs, and DSMBs a single, independently verifiable source of clinical truth for oversight and submission.
- Intellectual Property Protection via On-Chain Timestamping In multi-institution research consortia — increasingly common as immuno-oncology globalises across Boston, London, Bengaluru, and Singapore — blockchain timestamps establish irrefutable priority of scientific discovery before formal patent filings are complete. Every biomarker identification, CAR construct design, or novel neoantigen epitope mapping result is cryptographically signed and logged on-chain, creating a legally defensible record of inventorship that is verifiable across jurisdictions.
- Privacy-Preserving Federated AI Collaboration Blockchain-gated federated learning allows AI models to be trained collaboratively across institutions in Boston, London, Bengaluru, and Singapore without exchanging raw patient-level data. Each institution retains full data sovereignty; only model gradients — themselves carrying on-chain provenance attestation — are shared across the network. The resulting models achieve population-scale statistical power while satisfying the data residency and minimisation requirements of every participating jurisdiction simultaneously.
AI and blockchain are not competing investment priorities within a biotech data strategy — they are structurally complementary. AI operates on data to generate predictive value. Blockchain operates on data to generate verifiable provenance. One without the other produces either regulatorily fragile insights or trustworthy records with no analytical depth. Together, they constitute the complete data architecture that the next generation of immunotherapy approvals will require.7
FLEXBLOK: Enterprise Blockchain-as-a-Service for the Immunotherapy Pipeline
Historically, the principal barrier to blockchain adoption in biotech was not strategic conviction but technical overhead. Deploying a private permissioned network — selecting consensus mechanisms, configuring node architecture, mapping role-based access controls, and integrating with existing EDC and CTMS systems — required a dedicated distributed systems engineering team, a multi-month implementation timeline, and capital expenditure that most organisations could not justify outside of the largest late-stage programmes.
FLEXBLOK eliminates that barrier entirely. Built on Hyperledger Besu — a private, Ethereum-compatible distributed ledger conforming to Enterprise Ethereum Alliance (EEA) standards — FLEXBLOK delivers enterprise blockchain capabilities as a fully managed SaaS platform. It integrates directly with existing LIMS, CTMS, and EDC systems via developer-ready REST APIs, enabling teams with standard Web 2.0 engineering skills to embed blockchain capabilities without rebuilding their existing data infrastructure or hiring specialist distributed systems engineers.
- Production-Ready Deployment in Under 8 Weeks From signed agreement to a fully operational, compliance-grade clinical data network — validated in production by partners including Calym, a leading lymphoma research institute managing critical biosample lifecycles across multi-centre collaborations, who required a verifiable traceability system without a long, complex build-out.
- Decentralised Identifiers (DIDs) for Privacy-Preserving Patient Authentication W3C DID-compliant patient identity management eliminates centralised PHI repositories, reducing HIPAA and GDPR exposure while enabling pseudonymous cross-institutional patient matching across multi-centre trials — without compromising the ability to link longitudinal data for safety monitoring.
- Smart Contract Library for Clinical Workflow Automation Pre-built, audited smart contract templates cover dynamic consent management, protocol amendment versioning, SAE notification chains, and data access control — configurable to trial-specific SOPs via REST API without requiring Solidity development skills or in-house blockchain engineers.
- Built-In Regulatory Compliance Architecture Seamless auditability for FDA 21 CFR Part 11 electronic records requirements, ICH E6(R3) GCP compliance, GxP standards, and Asia-Pacific regulatory frameworks — all within a single EEA-standard private ledger. FLEXBLOK's hybrid on/off-chain model ensures PHI never touches the blockchain directly, satisfying both GDPR data minimisation principles and HIPAA technical safeguard requirements.
- AI Data Provenance Certification Aligned with OpenLineage Every dataset used to train or validate a clinical AI model receives an on-chain provenance certificate capturing its source, preprocessing history, consent status, and access events — fully aligned with the OpenLineage standard. This makes AI-generated biomarker signatures and response predictions directly auditable as primary regulatory evidence without additional retrospective documentation effort.
The biotech organisations driving the next generation of immunotherapy approvals — across precision oncology centres from Boston to Bengaluru, from London to Singapore — are not waiting for blockchain infrastructure to mature. They are building it now, because the regulatory and competitive pressure to prove data integrity is already here. FLEXBLOK makes that build accessible to every organisation in the pipeline.
Ready to Give Your Clinical Data the Trust Layer It Needs?
Deploy regulatory-grade blockchain infrastructure for your immunotherapy pipeline in under 8 weeks — integrating directly with your existing LIMS, EDC, and CTMS systems. No specialist blockchain engineers required.
Frequently Asked Questions
AI is accelerating immunotherapy across every stage of the pipeline. In neoantigen discovery, transformer-based models trained on MHC-I binding affinity databases (IEDB, NetMHCpan-4.1) and peptidome sequencing data can identify and rank patient-specific tumour-derived mutant peptides for vaccine inclusion in days rather than months. For CAR-T engineering, reinforcement learning optimises scFv domain selection for antigen binding specificity while minimising predicted off-tumour cytotoxicity and CRS risk. Multimodal AI models integrating TMB, MSI status, CD8+ TIL density, and radiomic features achieve AUC values of 0.70–0.95 across tumour types in prospective validation cohorts — enabling pre-treatment patient stratification for ICI therapy.
Read the peer-reviewed analysis in Clinical and Experimental Medicine →
Modern immunotherapy trials are data-intensive, multi-jurisdictional, and dependent on AI — a combination that amplifies existing data governance vulnerabilities. Patient data is distributed across CRO LIMS platforms, sponsor EDC systems, and academic biorepositories with no unified provenance trail. AI model training datasets lack the traceable lineage required by FDA 21 CFR Part 11 and the EU AI Act. And retrospective manual audit processes cannot satisfy ICH E6(R3) inspection standards at the speed and scale regulators now require. Without ALCOA+ compliant data architecture — Attributable, Legible, Contemporaneous, Original, Accurate, Complete, Consistent, Enduring, and Available — clinical AI outputs are commercially unusable even when scientifically valid.
Permissioned blockchain creates an immutable, independently verifiable ledger of every data transaction across the clinical lifecycle. Using Merkle-tree hashing and Byzantine fault-tolerant consensus, each event — patient enrolment, sample collection, consent update, protocol amendment, adverse event narrative — is timestamped on-chain at the moment of generation. The audit trail is tamper-proof and verifiable in real time by any authorised party without centralising raw patient data. This resolves cross-jurisdictional consent fragmentation, provides AI training datasets with regulatory-grade provenance certificates, and eliminates the selective reporting risk that undermines trial credibility with regulators and investors alike.
See the bibliometric evidence in Computer Methods and Programs in Biomedicine →
FLEXBLOK is an Enterprise Blockchain-as-a-Service (BaaS) platform built on Hyperledger Besu — a private, Ethereum-compatible distributed ledger conforming to EEA standards. It integrates with existing LIMS, EDC, and CTMS systems via developer-ready REST APIs, enabling teams to deploy dynamic consent management, immutable data provenance, decentralised identifiers, and smart contract automation in under eight weeks. Real-world biotech partners including Calym — a leading lymphoma research institute — have deployed production-ready infrastructure in that timeframe, describing it as a "production-ready infrastructure that strengthens trust, ensures regulatory readiness, and future-proofs data infrastructure."
AI models used in clinical decision-making are only regulatorily defensible if their training and validation datasets are traceable, appropriately consented, and demonstrably unaltered. FLEXBLOK's blockchain provides this provenance layer: every dataset input to an AI model receives an on-chain certificate recording its source, processing lineage, consent attestation, and access events — fully aligned with the OpenLineage standard for model lineage capture. This satisfies the audit requirements of FDA 21 CFR Part 11, the EU AI Act's high-risk AI provisions for clinical applications, and ICH E6(R3) GCP standards, transforming AI-generated biomarker signatures from scientifically compelling outputs into primary regulatory evidence.
Adoption is accelerating across all major immuno-oncology corridors. In the United States, FDA 21 CFR Part 11 enforcement and rising CRO accountability are driving demand across Boston, San Francisco, and San Diego. In the UK and EU, ICH E6(R3) revisions and the EU AI Act are compelling sponsors in London, Cambridge, Munich, and Basel to invest in verifiable data infrastructure. Singapore's HSA regulatory modernisation and the national RIE2030 research investment strategy are catalysing Southeast Asian adoption. In India, CDSCO alignment with international GCP standards and rapid expansion in Bengaluru and Hyderabad are generating strong demand for globally compliant clinical data frameworks that satisfy both domestic and international submission requirements simultaneously.